Hoe werkt een crawler?
Een crawler, ook wel een spider, bot of robot genoemd, is in feite een systeem dat op het internet wordt losgelaten om deze te gaan ontdekken en de content die het tegenkomt te bekijken.
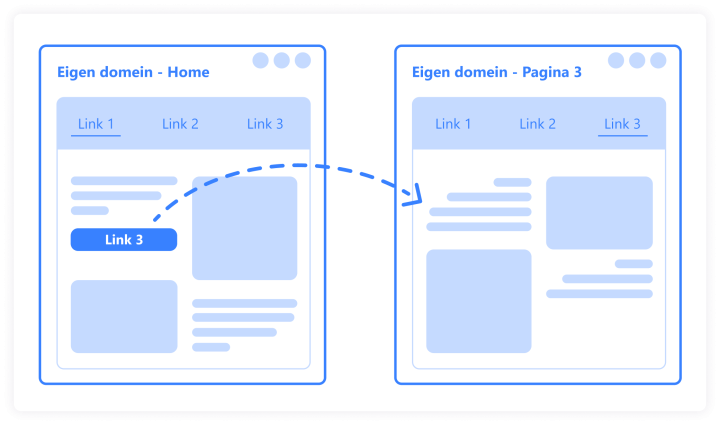
Wanneer het op een pagina een hyperlink naar een andere pagina tegenkomt (zie afbeelding), dan zal hij deze volgen en de volgende pagina bekijken. Zo crawlt de bot over het internet, als een spin in het web.
Het ontdekken en het bekijken van deze pagina's is de eerste stap richting indexatie, ofwel: 'het vastleggen van deze pagina's in de database van de zoekmachine'.